Conținutul duplicat reprezintă una dintre cele mai frecvente și, adesea, neînțelese probleme din optimizarea pentru motoarele de căutare (SEO). Acesta apare atunci când blocuri substanțiale de conținut de pe un site web se potrivesc sau sunt foarte similare cu conținutul de pe alte pagini, fie din cadrul aceluiași domeniu, fie de pe domenii diferite. Deși rar duce la penalizări manuale, conținutul duplicat poate dilua autoritatea paginilor, poate crea confuzie pentru motoarele de căutare și poate irosi bugetul de crawl, afectând în final vizibilitatea organică. Înțelegerea cauzelor, identificarea problemelor și aplicarea soluțiilor corecte sunt esențiale pentru a asigura o fundație tehnică solidă și pentru a maximiza potențialul SEO al unui site.
Ce este mai exact conținutul duplicat?
În esență, conținutul duplicat se referă la situația în care același conținut este accesibil prin mai multe adrese URL unice. Motoarele de căutare, precum Google, se străduiesc să ofere utilizatorilor o varietate de rezultate relevante și unice. Atunci când crawlerii întâlnesc mai multe versiuni ale aceluiași conținut, se confruntă cu o dilemă: ce versiune să indexeze și să afișeze în rezultatele căutării? Care este sursa originală și cea mai autoritară?
Este important de menționat că termenul „conținut” nu se limitează doar la textul dintr-un articol de blog sau de pe o pagină de serviciu. Poate include descrieri de produse, recenzii, pagini de categorii sau orice alt element textual substanțial. De asemenea, conceptul de „duplicat” nu înseamnă întotdeauna o copie identică, cuvânt cu cuvânt. Google folosește termenul „apreciabil similar” (appreciably similar), ceea ce înseamnă că și paginile cu diferențe minore, dar cu un nucleu de conținut identic, pot fi considerate duplicate.
Problema poate apărea în două contexte principale:
- Conținut duplicat intern: Când același conținut apare pe mai multe URL-uri din cadrul aceluiași site web. Aceasta este cea mai comună formă și este adesea cauzată de probleme tehnice neintenționate.
- Conținut duplicat extern: Când conținutul de pe un site este identic sau foarte similar cu cel de pe un alt domeniu. Acest lucru poate fi rezultatul preluării neautorizate (scraping), dar și al unor practici legitime, cum ar fi sindicalizarea de conținut sau utilizarea descrierilor standard de la producători.
Înțelegerea acestei definiții este primul pas pentru a demistifica problema și a aborda corect soluțiile, transformând o potențială vulnerabilitate SEO într-un aspect bine gestionat al strategiei digitale.
De ce este conținutul duplicat o problemă pentru SEO?
Impactul conținutului duplicat asupra performanței unui site în motoarele de căutare este subtil, dar semnificativ. Contrar unei credințe populare, existența conținutului duplicat nu atrage automat o „penalizare” din partea Google, cu excepția cazurilor flagrante de manipulare, cum ar fi crearea de domenii multiple cu același conținut pentru a domina rezultatele căutării. În majoritatea situațiilor, problemele sunt de natură tehnică și strategică.
Diluarea autorității și a semnalelor de ranking
Autoritatea unei pagini (adesea numită „link equity” sau „link juice”) este construită în principal prin backlink-uri de calitate. Când mai multe URL-uri prezintă același conținut, linkurile externe pot ajunge să fie distribuite între aceste versiuni. De exemplu, un site ar putea primi un link către `https://www.exemplu.ro/produs`, altul către `https://exemplu.ro/produs`, iar un al treilea către `https://www.exemplu.ro/produs?sesiune=123`. În loc ca toată autoritatea să se concentreze pe o singură pagină, ea este fragmentată. Această diluare slăbește capacitatea paginii principale de a concura eficient în rezultatele căutării.
Confuzie pentru motoarele de căutare
Când Google găsește mai multe pagini cu conținut identic, trebuie să ia o decizie. Algoritmii săi încearcă să identifice versiunea „canonică” sau originală, dar acest proces nu este infailibil. Acest lucru duce la mai multe posibile rezultate negative:
- Alegerea greșită a URL-ului: Google poate alege să claseze o versiune nedorită a paginii (de exemplu, una cu parametrii de tracking în URL) în detrimentul versiunii curate.
- Filtrarea rezultatelor: Pentru a evita afișarea de rezultate repetitive, Google va alege de obicei o singură versiune pentru a o afișa, filtrându-le pe celelalte. Dacă semnalele de autoritate sunt împărțite, este posibil ca niciuna dintre versiuni să nu obțină o clasare suficient de bună.
- Indexare inconsistentă: Motorul de căutare poate alterna între indexarea diferitelor versiuni, ducând la fluctuații de ranking.
Felul cum funcționează motoarele de căutare este complex, iar scopul lor este să organizeze informația eficient. Conținutul duplicat introduce zgomot și ineficiență în acest proces.
Consumarea bugetului de crawl
Fiecare site are alocat un „buget de crawl” – o cantitate limitată de resurse pe care Googlebot le dedică pentru a parcurge și indexa paginile site-ului. Dacă Googlebot își petrece timpul crawlând mii de versiuni duplicate ale acelorași pagini (generate, de exemplu, de filtrele de navigare dintr-un magazin online), va avea mai puțin timp și resurse pentru a descoperi și indexa conținutul nou și valoros, cum ar fi noile articole de blog sau paginile de produs adăugate recent.
Tipuri comune de conținut duplicat și cauzele lor
Problemele de conținut duplicat apar adesea neintenționat, ca urmare a modului în care sunt construite și gestionate site-urile web. Identificarea sursei este esențială pentru a aplica soluția corectă.
Cauze tehnice interne
- Versiuni WWW vs. non-WWW și HTTP vs. HTTPS: Dacă un site este accesibil la `http://exemplu.ro`, `https://exemplu.ro`, `http://www.exemplu.ro` și `https://www.exemplu.ro` și nu există redirectări automate către o versiune preferată, motoarele de căutare pot vedea patru site-uri separate cu conținut identic.
- Parametrii URL: Multe site-uri folosesc parametri în URL pentru tracking, sortare sau filtrare. De exemplu, `domeniu.ro/rochii?culoare=rosu` și `domeniu.ro/rochii` pot afișa conținut foarte similar, dar sunt URL-uri distincte. ID-urile de sesiune (`?sessionid=xyz`) sunt o altă cauză comună.
- Structura CMS-ului: Sistemele de management al conținutului precum WordPress pot genera duplicate în mod natural. Un articol poate fi accesibil la URL-ul său permanent (`/articol-nou/`), dar și pe pagina principală, în arhiva categoriei (`/categorie/seo/`), în arhiva de etichete (`/eticheta/marketing/`) și în arhiva lunară (`/2023/10/`).
- Pagini optimizate pentru print: Crearea unei versiuni `…/pagina/print` a unui articol generează un URL distinct cu același conținut.
- Site-uri de testare (Staging): Dacă un site de dezvoltare sau de testare nu este blocat corespunzător de la indexare (de exemplu, prin parolă sau prin meta tag-ul `noindex`), acesta poate fi descoperit și indexat de Google, creând o copie exactă a site-ului principal.
Cauze legate de conținut și strategie
- Descrieri de la producători: În e-commerce, este foarte tentant să se folosească descrierile standard furnizate de producători. Problema este că sute sau mii de alți retaileri fac același lucru, rezultând un număr masiv de pagini de produs identice pe internet.
- Sindicalizarea de conținut: Republicarea conținutului propriu (de exemplu, un articol de blog) pe alte platforme (precum Medium, LinkedIn Articles sau publicații de știri) este o practică legitimă de marketing. Totuși, dacă nu este gestionată corect (prin utilizarea tag-urilor canonice), poate duce la situația în care versiunea republicată depășește în ranking originalul.
- Conținut „boilerplate” extins: Termenul se referă la blocurile de text repetitive care apar pe mai multe pagini, cum ar fi informațiile din footer sau sidebar. De obicei, acestea sunt ignorate de Google. Însă, dacă pagini diferite au titluri și meta descrieri similare și conțin doar un paragraf unic, înconjurat de blocuri mari de text boilerplate, ele pot fi semnalate ca fiind duplicate.
Cum identifici problemele de conținut duplicat?
Înainte de a putea rezolva problemele, trebuie să le identifici. Un proces de diagnosticare riguros implică utilizarea mai multor instrumente și tehnici.
O primă metodă, simplă și accesibilă, este utilizarea operatorilor de căutare Google. Se poate lua un fragment de text unic și specific dintr-o pagină (între ghilimele) și se poate căuta pe Google folosind operatorul `site:domeniultau.ro`. De exemplu: `site:exemplu.ro „acesta este un text unic de pe pagina mea”`. Dacă rezultatele afișează mai multe URL-uri, este un indiciu clar al unei probleme de duplicare internă.
Google Search Console este un instrument esențial. În raportul „Pagini” (din secțiunea Indexare), se pot găsi URL-uri pe care Google le-a exclus din diverse motive. Categoriile relevante de urmărit sunt „Pagină duplicată fără o versiune canonică selectată de utilizator” și „Pagină alternativă cu etichetă canonică adecvată”. Aceste rapoarte oferă o perspectivă directă asupra modului în care Google percepe structura site-ului.
Pentru o analiză mai profundă, sunt necesare unelte specializate de crawling. Programe precum Screaming Frog SEO Spider sau Sitebulb pot parcurge întregul site, similar cu un motor de căutare, și pot genera rapoarte detaliate despre elemente duplicate, cum ar fi:
- Titluri de pagină (Title Tags) duplicate
- Meta descrieri duplicate
- Tag-uri H1 duplicate
- Hash-uri de conținut identice (care indică pagini cu conținut identic)
Aceste instrumente sunt indispensabile în cadrul unui audit SEO complet și ajută la identificarea problemelor la scară largă, în special pe site-uri cu mii sau zeci de mii de pagini. Pentru a verifica duplicarea externă (plagiatul), un instrument precum Copyscape este standardul industriei.
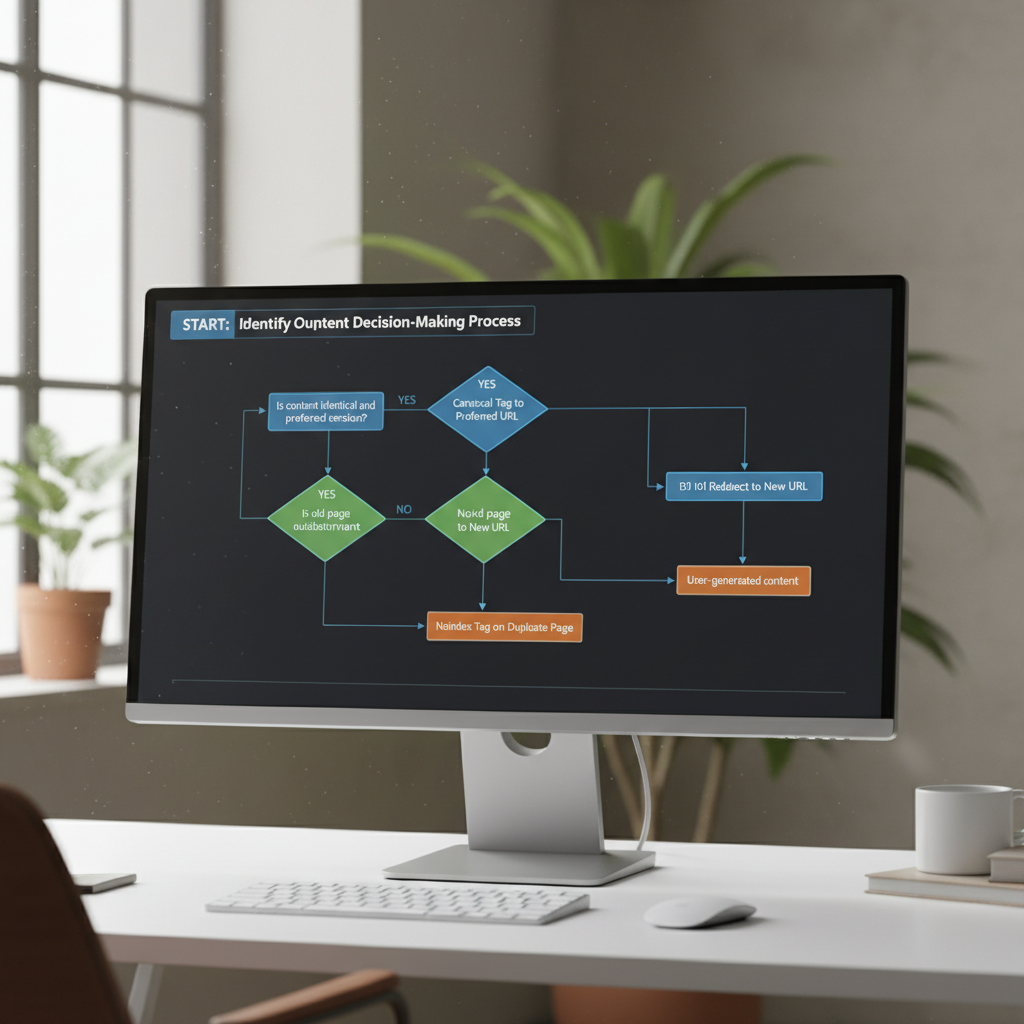
Soluții și bune practici pentru a rezolva și preveni conținutul duplicat
Odată ce problemele au fost identificate, este timpul să se implementeze soluțiile potrivite. Alegerea metodei corecte depinde de cauza specifică a duplicării.
Utilizarea tag-ului Canonical (rel=”canonical”)
Tag-ul canonical este probabil cel mai important instrument în lupta cu conținutul duplicat. Acesta este un element HTML plasat în secțiunea `
` a unei pagini, care indică motoarelor de căutare care este versiunea „preferată” sau „originală” a acelei pagini. Prin implementarea sa, toate semnalele de ranking (cum ar fi linkurile) de la versiunile duplicate sunt consolidate către URL-ul canonic.Exemplu: ``
Acest tag ar trebui implementat pe toate paginile duplicate, indicând către versiunea principală. Este soluția ideală pentru paginile cu parametri URL, paginile de sortare/filtrare care trebuie să rămână accesibile utilizatorilor, și pentru gestionarea conținutului sindicalizat (unde se poate folosi un canonical cross-domain pentru a indica sursa originală). Implementarea corectă a acestor elemente este un pilon al oricărei strategii de SEO tehnic.
Redirectări 301
O redirectare 301 este o instrucțiune permanentă care trimite atât utilizatorii, cât și motoarele de căutare de la un URL la altul, transferând în același timp majoritatea autorității (link equity). Este soluția potrivită atunci când o pagină duplicată nu mai are niciun motiv să existe independent.
Cazuri de utilizare tipice pentru redirectări 301 includ:
- Standardizarea domeniului (redirectarea versiunilor non-www, http și www/http către o singură versiune canonică, de exemplu `https://www.exemplu.ro`).
- Remedierea problemelor de trailing slash (redirectarea de la `domeniu.ro/pagina/` la `domeniu.ro/pagina` sau invers, pentru a menține consistența).
- Consolidarea unor pagini foarte similare într-una singură.
Meta Tag-ul „Noindex”
Tag-ul `meta name=”robots” content=”noindex”` instruiește motoarele de căutare să nu includă o anumită pagină în indexul lor. Aceasta este o soluție radicală, dar utilă pentru paginile care nu oferă nicio valoare în căutările organice, cum ar fi rezultatele căutărilor interne de pe site, paginile de „mulțumesc” după completarea unui formular, arhivele de autor sau de dată care nu generează trafic relevant.
Crearea de conținut unic
Soluția fundamentală și cea mai eficientă pe termen lung este crearea de conținut original și valoros. În special pentru magazinele online, rescrierea descrierilor de produse pentru a fi unice, informative și persuasive nu doar că rezolvă problema conținutului duplicat, dar aduce și beneficii majore în ceea ce privește ratele de conversie și experiența utilizatorului. Investiția în conținut de calitate este o componentă centrală a oricăror servicii SEO profesioniste, deoarece abordează problema de la rădăcină.
Gestionarea corectă a site-urilor multilingve și multi-regionale
Pentru site-urile care vizează audiențe din diferite țări sau care vorbesc limbi diferite, tag-urile `hreflang` sunt esențiale. Aceste atribute HTML îi comunică lui Google care este relația dintre paginile în diferite limbi sau pentru diferite regiuni. De exemplu, o pagină în engleză pentru SUA și o pagină identică în engleză pentru Marea Britanie nu vor fi considerate duplicate dacă sunt etichetate corect cu `hreflang`, deoarece Google înțelege că sunt destinate unor audiențe diferite.
O strategie proactivă pentru un conținut original și valoros
Gestionarea conținutului duplicat nu ar trebui să fie un exercițiu reactiv, realizat doar atunci când apar probleme de ranking. O abordare proactivă, integrată în strategia generală de SEO, este mult mai eficientă. Acest lucru implică stabilirea de la bun început a unei versiuni canonice a domeniului și implementarea redirectărilor corespunzătoare. Înseamnă, de asemenea, configurarea corectă a platformei CMS pentru a minimiza generarea de URL-uri inutile și utilizarea strategică a tag-urilor canonice pe toate paginile site-ului.
Mai presus de aspectele tehnice, fundamentul unui site de succes rămâne crearea de conținut autentic, care răspunde nevoilor publicului țintă. Prin combinarea unei fundații tehnice solide cu o strategie de conținut bine pusă la punct, problemele de conținut duplicat pot fi nu doar evitate, ci transformate într-o oportunitate de a consolida autoritatea și de a oferi o experiență superioară utilizatorilor și motoarelor de căutare deopotrivă.
Întrebări frecvente
Ce este mai exact conținutul duplicat?
Conținutul duplicat se referă la blocuri de text substanțiale care sunt identice sau foarte similare și care apar pe mai multe adrese URL, fie în cadrul aceluiași site (intern), fie pe site-uri diferite (extern). Acest lucru poate crea confuzie pentru motoarele de căutare cu privire la versiunea originală pe care ar trebui să o claseze.
Google penalizează site-urile pentru conținut duplicat?
În general, nu. Google nu aplică o „penalizare” pentru conținutul duplicat apărut neintenționat (de exemplu, din motive tehnice). În schimb, algoritmii săi filtrează rezultatele pentru a afișa versiunea pe care o consideră cea mai relevantă. Penalizările pot apărea doar în cazuri de duplicare manipulativă, în care se încearcă în mod deliberat înșelarea motoarelor de căutare.
Care este diferența dintre un tag canonical și o redirectare 301?
Tag-ul canonical (rel=”canonical”) este o sugestie pentru motoarele de căutare, indicând versiunea preferată a unei pagini, în timp ce pagina duplicată rămâne accesibilă pentru utilizatori. O redirectare 301 este o comandă care trimite permanent atât utilizatorii, cât și motoarele de căutare de la un URL la altul, URL-ul original nemaifiind accesibil.
Cum pot verifica rapid dacă site-ul meu are conținut duplicat?
O metodă simplă este să copiați un fragment de text unic de pe o pagină, să îl puneți între ghilimele și să căutați pe Google folosind operatorul `site:domeniultau.ro „fragmentul de text”`. Dacă apar mai multe rezultate din site-ul propriu, aveți o problemă de duplicare internă.
Descrierile de produse de la producători sunt considerate conținut duplicat?
Da. Dacă folosiți aceleași descrieri ca zeci sau sute de alți retaileri online, paginile dumneavoastră de produs vor fi considerate duplicate. Cea mai bună practică este să rescrieți aceste descrieri pentru a fi unice, adăugând valoare prin informații specifice, beneficii și un ton de voce propriu brandului.